
Este artículo sirve como una introducción a la Alta Disponibilidad en equipos IBM POWER SYSTEM con Sistema Operativo IBM i (AS/400 – iSeries). Para empresas que quieren entender las tecnologías que hay detrás de estos esquemas y estén evaluando el costo/beneficio de implementar Alta Disponibilidad en su operación.
Mira el webinar:
Como su nombre lo indica, Alta Disponibilidad (o HA por sus siglas High Availability), es la capacidad de tener sus sistemas IBM i siempre (24/7) funcionales para la operación del negocio. Todas las compañías enfrentan el reto de implementar HA de formas diferentes. En primera instancia, porque la continuidad operativa tiene diferentes criticidades y costos para cada empresa ya que depende totalmente de la operación y giro del negocio.
Probablemente para una empresa de logística, que necesita tener registros y visibilidad de sus embarques 24/7, sea más crítico contar con un esquema de HA que para una empresa que comercializa muebles únicamente de lunes a viernes en un horario de 9 am a 5 pm. La empresa de logística necesita mantener sus aplicaciones y bases de datos funcionales en el IBM i para evitar fallas en el servicio que ofrecen a todos los niveles (empleados, clientes, socios, etc.).
Está claro que cada empresa tiene diferentes prioridades respecto a la Alta Disponibilidad en su IBM i. Sin embargo, en los últimos años la necesidad de contar con un esquema HA ha ido aumentando en diferentes industrias. El notable incremento en comercio electrónico, o prácticas como servicio al cliente 24/7, han aumentado la necesidad de tener los sistemas disponibles en todo momento sin importar el giro del negocio. Hoy en día, cada vez son menos los negocio que se pueden dar el lujo de dormir su operación los fines de semana.
Antes de entrar en detalle sobre HA en el IBM i, hablemos rápidamente sobre los conceptos e impactos de estar fuera de línea, o de ‘caídas del sistema’, y estrategias para mitigar las pérdidas por estas caídas.

Gerentes y directores de diferentes áreas de las compañías suelen sorprenderse cuando suman los costos directos e indirectos de la interrupción de actividad para el negocio. Al principio, pueden asumir que si un sistema está inactivo por varias horas, o incluso un día completo, es una gran molestia pero un riesgo tolerable, siempre y cuando estas interrupciones sean un evento atípico. Pero más allá de lo molesto, existen factores críticos que pueden afectar incluso la salud financiera de cualquier empresa, sin importar su tamaño.
No existe una fórmula definitiva para determinar el costo de una caída en el sistema, como se decía al inicio, todo depende del negocio y su operación. Sin embargo, para sacar un aproximado es posible hacerlo con la siguiente fórmula:
También se tendría que considerar el momento, es aún más grave si la caída llegara a ocurrir en algún día de temporada alta. No hay forma sencilla de determinar las pérdidas de forma exacta, pero a resumidas cuentas, es más de lo que uno se suele imaginar.
En conclusión, no hay nada peor que tener downtime de manera imprevista. Por otro lado, las operaciones del TI necesitan tiempo fuera de línea para llevar ciertas actividades, no es frecuente, pero para este caso se requiere una planificación adecuada. Es por tal motivo que el downtime se tiene que abordar de dos formas diferentes: el imprevisto y el planeado.
El IBM i es uno de los sistemas más confiables y robustos en el mercado. Las probabilidades de que un IBM i falle, por motivos atribuibles directamente al servidor POWER, son prácticamente nulas. Sin embargo, hay infinidad de factores externos que podrían provocar donwtime en un IBM i, por mencionar algunos:
Es por tal motivo que los sistemas IBM i no están exentos de sufrir caídas que, además del tiempo fuera de línea para el negocio, conlleva potenciales riesgos de pérdidas de información.
Para el caso del downtime planeado, es una historia totalmente diferente. Existen diferentes motivos por los cuales se requeriría frenar la operación de nuestros sistemas, algunos de ellos podrían ser:
Cuando se presentan estas situaciones, es trabajo del equipo de TI hacer toda la planificación para afectar en lo más mínimo la operación del negocio. Se pueden crear respaldos de manera oportuna, e informar a los usuarios que el sistema no estará funcional por una ventana de tiempo determinada. Usualmente ocurren en fines de semana o días festivos, nuevamente, todo depende de la naturaleza del negocio.
Sin embargo, independientemente de que el downtime sea planeado o imprevisto, contar con un esquema de HA en su IBM i reduce significativamente los riesgos y potenciales errores al momento de volver a levantar la operación una vez termina el downtime.
En ocasiones, el downtime planeado sin HA también puede generar problemas en la operación y representar pérdidas financieras. Por ejemplo, migrar a la nube sin haber hecho las pruebas pertinentes previo a migrarse y tener que volver hacia servidores on-premise porque se termina el tiempo disponible.
Existen distintos métodos mediante los cuales se puede regresar a las operaciones regulares después de tener tiempo fuera de línea. La efectividad entre uno y otro dependerá de las circunstancias, el motivo por el cual hubo downtime (planeado o imprevisto). Cada uno de los métodos tiene un costo y riesgo distinto.
Para poder determinar qué tan bueno o malo es un método a comparación que otro, debemos tener claro los términos DRP, RPO y RTO. Son términos que pueden escucharse muy técnicos pero en realidad son muy fáciles de entender:
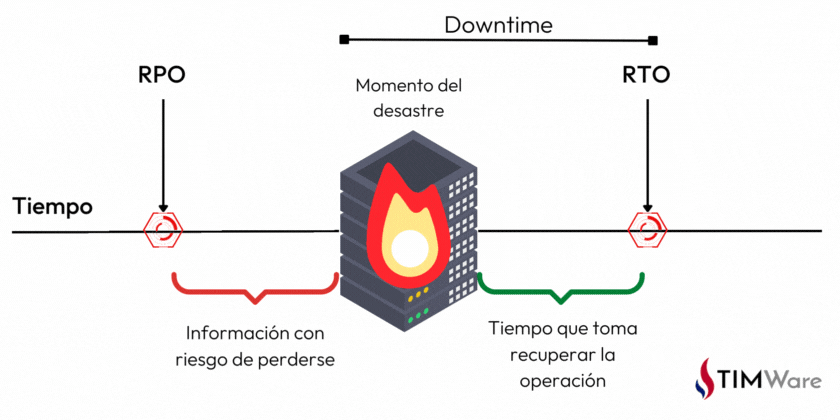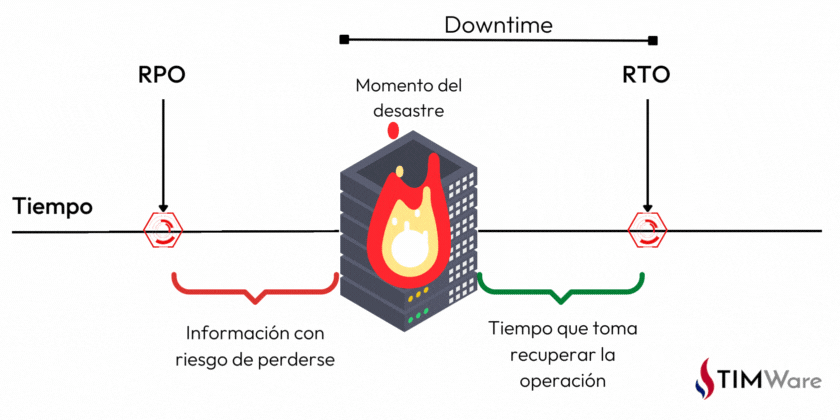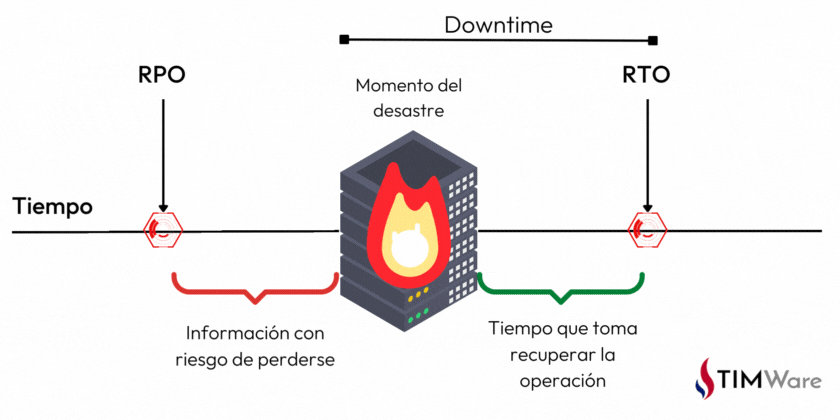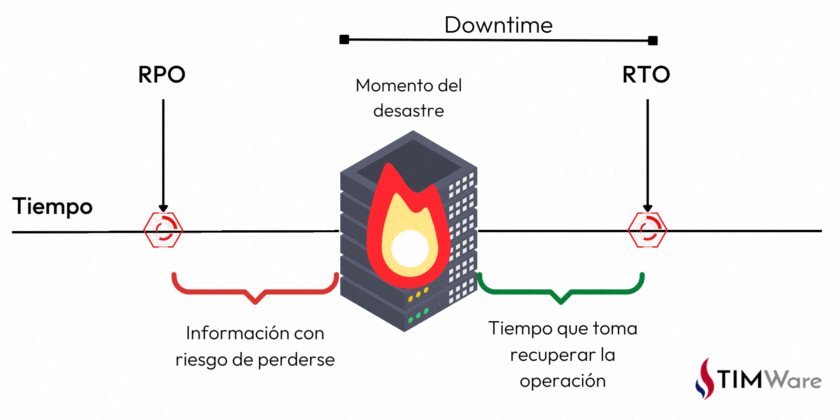
Por otro lado, también es importante considerar que los esquemas HA eficientes necesitan forzosamente dos máquinas; una productiva y otra de respaldo (DRP). En caso de que falle la productiva, el negocio debe tener la posibilidad de seguir operando en su DRP, con todas sus implicaciones.
Este es el método tradicional de ejecutar respaldos (backups). Si eres un tanto nuevo en esto de los Sistemas IBM i, seguramente te sonará muy obsoleto escuchar el término “cinta”. Sin embargo, es una de las formas más efectivas y menos caras de mantener la información segura.
Hay muchas compañías que de forma periódica realizan respaldos en cinta y los almacenan en algún lugar seguro por años. Es una forma extremadamente eficiente para mantener información a largo plazo y con bajo riesgo de perderla. Sin embargo, para garantizar la continuidad del negocio implica muchos riesgos. Aunque claro que con un esquema de nube no aplicaría, pero esa es otra historia.
En caso de llevar este método para nuestro DRP, el RPO sería la periodicidad con la que se hacen los respaldos en cinta. Si se hacen respaldos una vez al día, el riesgo de pérdida de datos será toda la que se genera a partir del respaldo. Y el RTO dependería de nuestra capacidad de volver a levantar el servidor, y el tiempo que tome restaurar la cinta del último respaldo. El costo financiero de usar este esquema es bajo, pero el riesgo que implica para el negocio no es precisamente el deseable.
Este método se recomendaría para downtime planeado únicamente, y aún así tiene sus áreas de oportunidad.
El Sistema IBM i cuenta con una función a manera de “diario” llamados journal. En éste, el sistema registra todos los movimientos que ocurren en las bases de datos y los objetos. Este método básicamente reconstruye todos los movimientos de nuevo en el mismo sistema o en un sistema alterno.
Es como si a raíz de un diario que escribimos todos los días sobre nosotros, tengamos la capacidad de volver a ejecutar las acciones que hicimos a lo largo del tiempo y reconstruirlo todo exactamente como lo hicimos en la primera ocasión. Como tal, este es el método más eficiente y efectivo para un DRP, y más adelante hablaremos y nos enfocaremos en explicar por qué el RPO y RTO sería el más efectivo. Pero hablar de ello también implica hablar de las soluciones que llevarían a cabo el proceso, y en este momento sólo podría ser confuso.
Este método, al igual que el respaldo en cinta, es una forma de implementar el DRP a nivel de hardware ya que ambos implican la intervención física de algún elemento externo para llevarse a cabo. En el caso de las cintas, las cintas en sí y lo que implica tener a una persona que haga los cambios de cinta de forma física. Para la de protección de discos, dependeríamos de los discos físicos en los que se respalda la información.
Al momento que configuran nuestro equipo IBM POWER SYSTEM, se establece la configuración de las unidades de disco. La configuración más popular es la de RAID 5, estas configuraciones implican estar respaldando información en distintas unidades de los mismos discos en el equipo. En caso de que falle un disco, el sistema podrá restaurar esa información con base en información de otros discos.
Aquí puedes encontrar una explicación más detallada. Este método atiende principalmente a las potenciales fallas del sistema que pudieran ocurrir por fallas en las unidades de memoria. Útil si el equipo que se cae es el mismo que se levantaría, en caso de contar con un equipo alterno para desastres no sería tan eficiente, igual que ocurre con respaldo en cinta.
Hoy en día el auge de la nube (cloud) es innegable, cada vez es más común este tipo de operaciones en vez de en sitio (on-premise). Por su puesto la nube no quedaría fuera de los esquemas de DRP, existen empresas que te ofrecen la capacidad de tener tu DRP en la nube para que sea más eficiente en cuanto a costo.
Una de los factores más interesantes de la nube es que el costo va de acuerdo a lo que utilizas. Cuando uno adquiere un IBM POWER SYSTEM tiene que ser con ciertas configuraciones de capacidad. Puede ser un procesador potente con determinada cantidad de cores (CPU’s). Esta capacidad puede ser un poco flexible pero no tanto como en nube. Puedes comprar un POWER con un procesador de 8 cores, los utilices o no, tienes que pagarlos. En la nube es bajo demanda, puedes pagar 1 core si tienes poca actividad y contratar 16 si los requieres por alguna razón en particular.
Esta estrategia para tu DRP consta en estar replicando información a un sistema en nube con bajos recursos contratados, y en el caso de desastre, migras tu operación hacia la nube y contratas el poder de computo necesario para que tu operación funcione tal cual lo estaba haciendo como en tu máquina on-premise.
Como podrás ver, los diferentes métodos pueden conllevar muchas diferencias en cuanto al RPO y RTO. Hay demasiados factores involucrados para explicarlos, y nos estaríamos desviando un poco. La clave aquí, es la forma en la que se puede replicar la información de la máquina productiva hacia la de respaldo y lo que conlleva migrar la operación hacia la máquina de respaldo. Y es de lo que hablaremos a continuación.
Todos los esquemas HA deben contar con los siguientes componentes para garantizar la continuidad del negocio:
Como se mencionó anteriormente, los esquemas HA requieren de 2 máquinas (productivo & DRP). Por razones obvias, cada máquina debería estar instalada en diferentes lugares que estén relativamente lejos. Para lograr que el RPO sea lo mínimo posible, la información en ambas máquinas debe estar tan igual como se pueda.
Para ello, se requiere establecer comunicación TCP/IP entre ellas para que el productivo pueda estar replicando grandes cantidades de información de manera confiable hacia el DRP. En esta transferencia de información, el ancho de banda juega un rol fundamental para la paridad de la información entre ambos equipos. Si la cantidad de información es demasiada y el enlace de ancho de banda es pequeño, la información llegará al sistema DRP más lento, afectando negativamente al RPO. La distancia física entre ambos servidores también afecta debido a la latencia en la transferencia de información.
La información del equipo productivo debe transferirse de forma eficiente hacia el DRP para tener un RPO mínimo.
Ya tenemos claro que se necesita enviar información del productivo al DRP, ahora necesitamos conocer el proceso que existe detrás de este envío de información.
Una vez establecida la comunicación entre ambos sistemas, el siguiente componente es un motor que replique o imite (‘mirror’) los movimientos del equipo productivo hacia el DRP y entre más se replique en tiempo real mejor. La forma de hacer esto es mediante el método de journalización (journaling). ¿Recuerdas que hablamos de ello en puntos anteriores? Pues aquí volvemos a tocar ese tema. Este modelo de replicación es a nivel lógico.
Hoy en día no hay ninguna función por defecto en el IBM i que permita replicar la información por medio de la journalización. Para ello se requieren herramientas de terceros que llevan a cabo esta tarea. Estas soluciones toman las entradas de los journals, los envían hacia el DRP y replican todas las acciones de las entradas para igualar al DRP hacia el productivo. Esto se le conoce como ‘mirroring’, porque no se está enviando la información (objeto) como tal, sino que se envían las ‘instrucciones’ a ejecutar en el DRP para lograr replicar al productivo. Algunas de estas soluciones pueden ser:
Aquí entra un de los factores más importantes de los esquemas HA en IBM i, y que constantemente se ignora o pasa por alto por los equipos de TI. El proceso de journalización requiere poder de computo de los equipos, este proceso no funciona por defecto en el IBM i, hay que activarlo. Y cuando se activa, afecta indirectamente el rendimiento del equipo. Este punto es importante ya que en ocasiones orilla a contratar más cores o, peor aún, comprar equipos con procesadores más grandes porque el uso de CPU llega a cantidades arriesgadas (arriba del 80%).
Lo peligroso es que las herramientas para detectar el uso de CPU por cada aplicación en el IBM i, como performance tools, no distingue las afectaciones generadas por el proceso de journalización ya que afecta las aplicaciones de forma indirecta.
Cuando se inicia el proceso de journalización, esencialmente se inicia un proceso el cual ‘vigila’ los objetos, y va registrando todos los movimientos en una entrada de journal. Cuando ocurre cualquier cambio en algún objeto, el proceso registra los detalles de cada cambio que ocurre. Como tal el proceso de registro de entradas en el journal es extremadamente eficiente, el volumen de entradas a registrar es la que termina afectando el performance de los equipos.
El proceso de jounalización registra absolutamente todos los movimientos. Incluido movimientos que no afecten o modifiquen los objetos, por ejemplo, si un usuario consulta un objeto (aunque no le haga cambios) se generará una entrada de journal. Y aquí es donde es importante distinguir dos esquemas de réplica diferentes.
Soluciones como MIMIX, Robot HA, o ITERA, utilizan la replicación mediante journal remoto. Es decir, que el motor de la aplicación vive en el sistema de DRP. Esto significa que el sistema productivo estará enviando absolutamente todas las entradas del journal de productivo hacia el DRP, y una vez en el DRP, la solución se encargará de procesar y replicar todos los movimientos recibidos en el sistema DRP para así igualarlo al productivo.
En el proceso, las soluciones llevan a cabo un ‘depurado’ de las entradas que se reciben en el journal. Esto porque no se requieren replicar entradas que no modifiquen los objetos, como el ejemplo de la consulta que hablamos anteriormente.
El inconveniente que presenta este esquema de replicación es que se envían absolutamente todas las entradas del journal, y es hasta que llega al DRP que la aplicación depura las entradas que necesitan. Esto afecta el consumo de ancho de banda, como se envía toda la información (incluso la innecesaria), el uso de ancho de banda sería lo que afectaría más. Si el ancho de banda es pequeño vs la información que transmite, afectará la diferencia de la información entre ambos sistemas (alto RPO).
Soluciones como Assure Quick-EDD utilizan el esquema de replicación de journal local. La explicación es sencilla, el motor de la aplicación vive en el sistema productivo en lugar del DRP.
La diferencia principal es que esta solución lleva a cabo el depurado de journals de manera local, por lo que las entradas de journals enviadas hacia el DRP serán únicamente aquellas que representen algún cambio en los objetos. En pocas palabras, sólo se envían los cambios (deltas) para que se repliquen en el DRP, optimizando considerablemente el uso de ancho de banda, permitiendo tener un RPO reducido ahorrando costos en el ancho de banda del enlace.
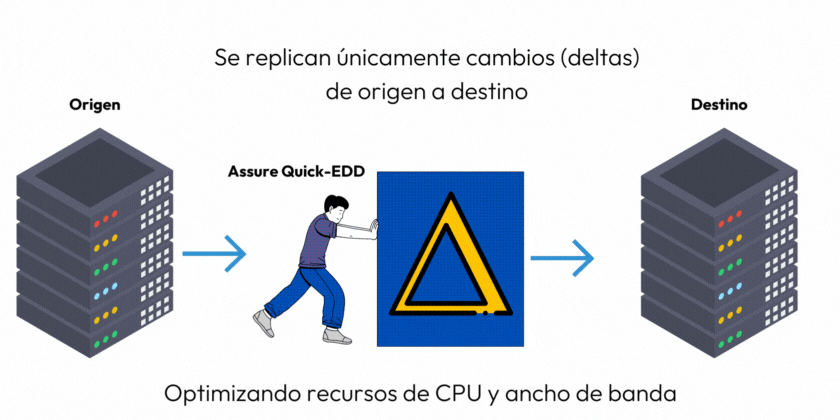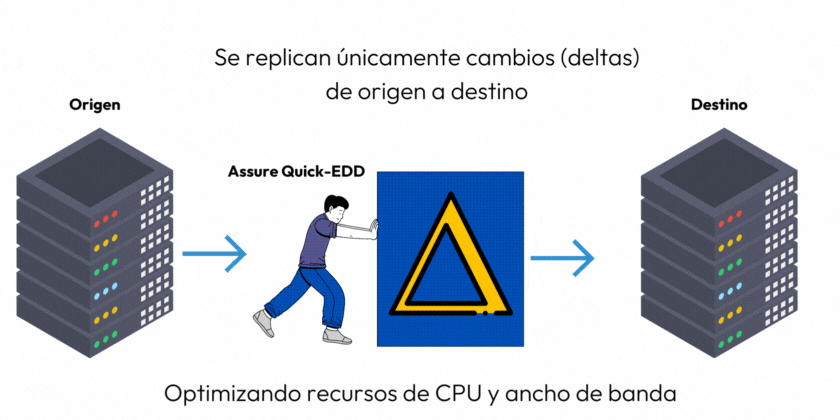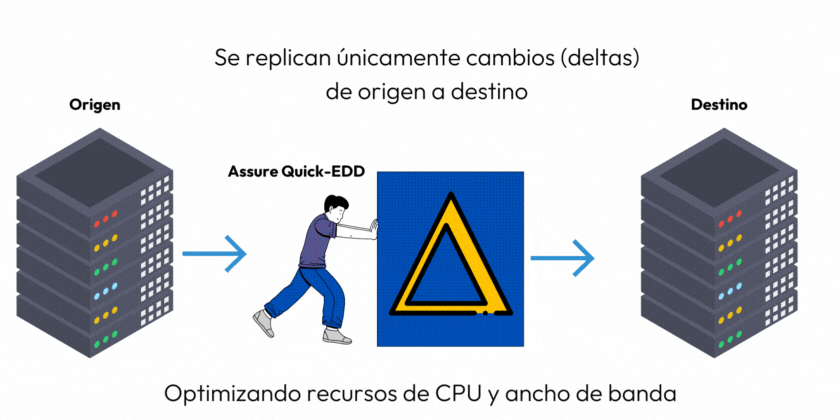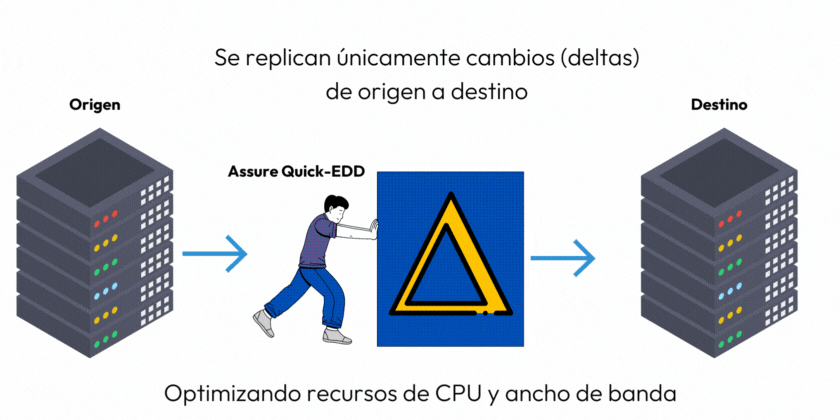
Una vez que establecida la replicación entre sistemas, se necesita un mecanismo para monitorear continuamente retrasos, interrupciones y problemas de integridad de datos en el proceso de comunicación.
Tener un proceso de monitoreo que garantice la integridad de la replicación es importante. De lo contrario, en caso de un fallo, su capacidad para usar de manera confiable el sistema DRP podría verse afectada. Está la posibilidad de que existan problemas dentro del proceso de replicación, ya sea retrasos, retransmisiones de datos debido a redes en la red o incluso errores de comunicación que escapan a la detección por parte de la red de comunicación misma. Si surge algún problema, debería ser evidente en las pantallas de monitoreo (o incluso alertar a un operador de sistema si la gravedad lo requiere) y luego intentar corregir automáticamente el problema.
Las capacidades de ‘auto-curación’ son cruciales para la fiabilidad y la facilidad de uso de una solución HA para IBM i. Por ejemplo, la solución HA debería determinar automáticamente si un objeto en el sistema de respaldo está desincronizado con el mismo objeto en el sistema de producción. Si es así, la solución debería iniciar el proceso de re-sincronización del objeto volviendo a copiar ese objeto desde el sistema de producción hasta el sistema de DRP y aplicando todas las entradas necesarias del journal para actualizarlo. Y debería hacer esto sin detener o ralentizar la replicación continua de otros objetos.
Las soluciones HA deben depender lo menos posible de procesos manuales y contar con procesos automatizados para ‘resanar’ la réplica en caso de inconsistencias.
Todas las funciones de una solución HA descritas hasta este punto existen principalmente para minimizar el downtime planeado o imprevisto rápidamente, haciendo disponible a los usuarios un sistema de respaldo completamente sincronizado y funcional. Esta es la funcionalidad básica requerida de todas las soluciones de alta disponibilidad.
El proceso de mover a los usuarios a un sistema de respaldo se llama un switchover o un cambio de rol, porque el sistema de respaldo asume esencialmente el papel del productivo durante el tiempo que le tome restablecerse correctamente.
Una vez establecido tu esquema de HA, es de vital importancia llevar a cabo de forma periódica (un par de veces al año) una cambio de rol de prueba. Esto para verificar que su esquema de HA realmente es efectivo ante cualquier desastre, por supuesto se tiene que llevar a cabo bajo un ambiente controlado. Un cambio de rol generalmente incluye los siguientes procesos:
La forma de llevar a cabo estas acciones puede variar dependiendo la solución HA que elijas, es importante que evalúes este proceso en las distintas aplicaciones para poder tomar la mejor decisión.
En TIMWare tenemos más de 20 años de experiencia implementando esquemas de HA en clientes de distintas industrias con la solución Assure Quick-EDD. En nuestra experiencia podemos asegurar que es la solución más efectiva y eficiente para HA. Mantiene una réplica confiable, y no consume demasiados recursos para poder contar con un RPO y RTO de minutos e incluso segundos. Todo sin exigir recursos humanos para la administración de la réplica, ni dependiendo de nuestra intervención para hacer cambios de rol y mantener una alta calidad en la réplica.
